AWS Glue – The Sticking Points


TL; DR
AWS Glue is a way to simplify running ETL pipelines for AWS Redshift, but there are sharp edges in the development process that you want to be aware of before starting your build.
The Dream – Server-less Speed and Simplicity
Set the stage
Picture this, near real-time data flows seamlessly from source systems to a data lake and is then packaged up and placed into a data warehouse. From there, the data is ready for a reporting and/or analytics system to easily query and extract the data it needs to provide a person with the exact information they need or want to know for their specific business inquiry. Easy, right?
When I joined our team here at Teaching Strategies, we were already using the AWS platform, S3 as the technology for our data lake, and Redshift for our data warehouse. Most of our data was sourced from a relational database using DMS to capture data changes, package it into Parquet files, and drop those files into S3. Redshift Spectrum was the mechanism we used to pull data from S3, transform it, and deposit it into Redshift. The orchestration was done by Lambda functions which called stored procedures in Redshift. This worked in theory, but in practice we encountered errors in Redshift that even Amazon Web Services experts struggled to resolve. So, our thought was, can we simplify this process?
Starting the journey
After talking with our AWS architecture team and leaning on my experience with PySpark on EKS, Big Query, Dremio, Postgres, etc., it seemed like we could make things a lot easier just by using Redshift Spectrum with our existing queries. Initial speed tests of this approach quickly proved that this was not going to work because of all the joins across multiple S3 folders, which each contained sub folders. We were in the range of multiple minutes for a query to complete. One way to improve this would have been to change our partitioning scheme, but we wanted to try to leverage the structure that DMS was generating.
So, which ETL approach could we apply to our existing stored procedure logic to scale the large workload into steps? I have used PySpark and EKS with Hive queries in the past. That approach has a lot of complexity, and I was looking to reduce complexity. When I shared this information with our AWS architecture team, they recommended that we use Glue. Glue provides server-less access to PySpark-like capabilities; with Glue, we do not need to worry about setting up an orchestration layer, tuning compute nodes, or messing with cluster setup. Sounds like a promising idea, I thought. Let’s do this!
Facing Reality – Getting Sticky With Glue
Hey, it’s like SSIS!
Upon a cursory review of Glue, it looked to be simple. It had a visual component builder named Studio, which reminded me of my days building ETL pipelines with SSIS. When you build your pipeline with the visual builder, Glue translates it into a Python script. I said to myself, “Great, this tool brings the simplicity of a visual builder and the power of Python together!” That excitement did not last long. Turns out, this process—using visual builder to translate your pipeline to Python script—is a one-way trip. I was hoping that, if the Python code followed the pattern created by the visual builder, we could switch from the Python script back to the visual builder, but that is, unfortunately, not the case with Glue. At the time of writing this, the visual builder will create a script, but when you want to modify it, or even when you want to deploy that Glue job from source control, you will not be able to do so using the visual builder. This is most unfortunate because Glue Studio has a nice Preview Data feature that enables you to see data results at each step of the process.
Back to Python coding
Due to the previously mentioned limitation of the visual builder in Glue Studio, the team went to work writing a few Glue jobs using the Python code method. This seemed like a reasonable way to approach the challenge until we started encountering issues in our code. The process of using Glue Studio to make code changes by running the script, waiting for an error to appear, opening the CloudWatch logs, and then scanning through the logs to see which Python code had failed—all without the modern assistance of intelligent suggestions—was quite cumbersome and time consuming. Compared against using a debugger and breakpoints with your typical Python code, this was quite a frustrating experience. AWS also offers the option to use Notebooks in the Glue module, but when the team tried it, it was far enough away from the Jupyter Notebook experience that it did not prove to be as useful as we had hoped. We also looked at using the Glue Docker image for local workstation development. This did allow us to use VSCode for intelligent suggestions, but the initial startup process of the container was slow, and access to intelligent suggestions alone did not feel like enough of a gain to warrant all the setup we would need to do per workstation.
After finally getting a few Glue jobs setup using Python scripts, we noticed that the time it took for a job to complete was around 30 minutes for our medium-sized ETL pipeline. This was using our lower environment, which has only a subset of data from our production environment. This issue brought us back to the same data partitions problem that we experienced when attempting to use only Redshift Spectrum. Scanning all of the files in the S3 folder of a particular data set was not going to work on our large jobs—not with our goal for near real-time data.
Redshift will save us
We needed to solve our partition problem. When we discussed this situation within the organization, a senior technology leader mentioned that in the past (and with success), he had used the approach of delta sets, intermediate tables, and final tables within the data warehouse. With this approach, we could leverage the power of keys within Redshift to avoid scanning all the data in a particular S3 location.
Cool, I thought, so I can leverage the orchestration and bookmark functionalities of Glue and the processing efficiency of Redshift. This led me to setup views in Redshift that would allow me to quickly add the delta set from Glue to the intermediate tables via the bookmark functionality. Once I had the delta set in the intermediate tables, another view would use the logic from the initial stored procedures to combine and transform the data. From there, a view would calculate the rows that exist from the intermediate tables and subtract the ones that already exist in the final tables. This approach is fairly simple to understand and develop, and it is flexible enough that you can do whatever SQL based logic you need within the intermediate view. This had to be our answer, I thought. Let’s go with it!
Glue Studio + Redshift = so you’re telling me there’s a chance
The process for building out a Glue job with the visual builder started out a little bumpy. When we implemented the job to convert S3 objects to intermediate tables, we ran into issues with Glue inserting columns by order instead of by name into Redshift. I was hoping that this would work; if I selected a subset of columns from the source, then I wanted that subset to map to the same columns in the Redshift target. Unfortunately, the Redshift target took the columns provided and mapped only to the first columns in the target table. So, in theory, we could map to a subset of columns if they all happened to be the first columns in the Redshift target table and if we were not using any columns that followed those initial columns. Also, we found that the only way to ensure that the columns were ordered correctly was to use the ApplyMapping transformation component before using the Redshift target component. After contacting AWS, we did find that there was a way to use a subset of columns, but it would require us to use a Glue function that was only available in the Python code format, which would prevent us from being able to use the visual builder.
Data types, the final frontier
Beyond the mapping issue, we ran into some integer differences between what Glue Catalog supports and what Redshift supports. In our Parquet files, we had some integers below the common INT32. Glue Catalog would map these correctly to byte, smallint, or tinyint, but when we would try to insert these into Redshift, we would only see nulls in the target table. Glue did not fail the job, but instead simply chose not to insert the data. Our team tried multiple ways around this issue: changing the schema in Glue Catalog, changing the mapping in the ApplyMapping transform and SQL Transformation, and using Custom Transformation. We settled on Custom Transform (I will share the code in the Moving Forward section of this article) because we could use the same generic code for every Glue job, whereas the SQL Transformation would require us to change each one. The other two approaches did not work.
Another integer-related data-type issue we encountered was that one of our Parquet files had an unsigned integer of 64 bits. We discovered this because Glue uses Spark as the base layer for loading information. Spark cannot handle UINT64 by default, and so the job would fail. There is a way to configure Spark to enable successful loading of UINT64 data types, but you cannot control that through the Glue connector. This meant that we would need to change our pattern for loading this specific pipeline and, as a result, we would not be able to easily use the bookmark feature for Glue. Our resolution for this was to change the way the process was creating the source files. Regaining control over the source file types meant that we would not need to write an intermediate process or implement the Spark connector in the job instead of the Glue connector, which we preferred.
Save your work
Lastly, the visual builder in Glue can only be used to create an initial build out or to find the Python code pattern for a component. There are also Glue components that do not have a visual builder representation. This means that there is no way to save the visual representation of a Glue job in source control. We store the Glue Python code in our Git repository, but apart from using a framework like AWS, Cloud Development Kit, Terraform, etc., a code-based solution for storing the other Glue configuration items does not exist. We leverage Terraform across our organization, which made it a logical storage choice, but it created another hoop for us to jump through.
Now, on to the next section where I will summarize the working setup.
Moving Forward – Leveraging Strengths of Components
Our team has successfully created data pipelines that move data from our S3 lake to our Redshift warehouse using Glue. Currently, we use a collection of Glue jobs to translate data lakes to intermediate tables and a set of Glue jobs to convert intermediate tables to final tables. We place the jobs on a cron schedule (which will, in the future, trigger jobs from other jobs). By putting all of the transformation logic into the delta set views in Redshift (which determines which rows need to be added to the final table), we enable the usage of these two simple patterns in Glue.
Part 1:
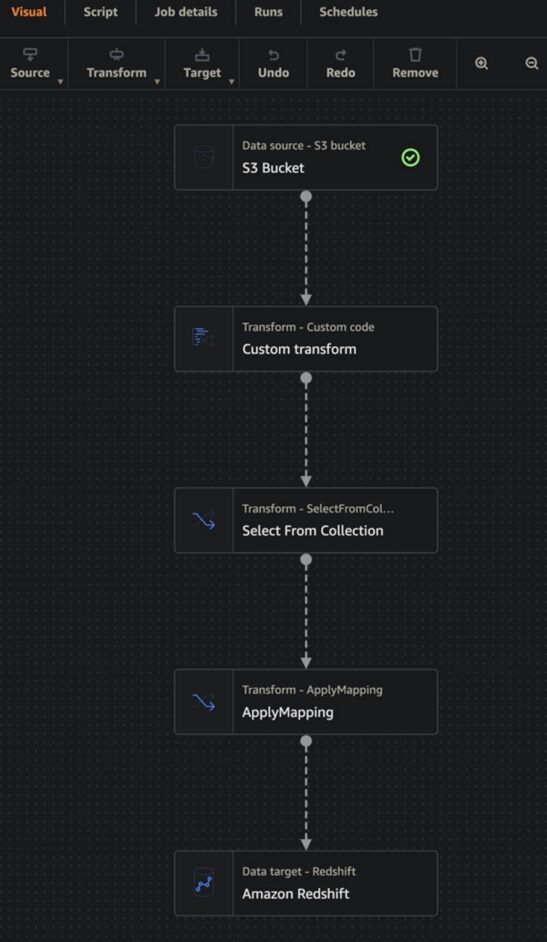
Here are the components and steps that we use to convert our data lake to intermediate warehouse tables using visual builder patterns along with a screenshot from Glue Studio:
- S3 Bucket (S3 Source using Glue Data Catalog table created by Glue Crawler)
- Custom Transform (used to convert byte and short integer types into integer type for Redshift to use)
def MyTransform (glueContext, dfc) -> DynamicFrameCollection:
from datetime import datetime
from pyspark.sql.functions import lit,col
df = dfc.select(list(dfc.keys())[0]).toDF()
for field in df.schema.fields:
if str(field.dataType) in ('ByteType','ShortType'):
df=df.withColumn(field.name,col(field.name).cast("integer"))
df_w_timestamp = df.withColumn("etl_log_timestamp_utc", lit(datetime.now()))
df_etl_log = DynamicFrame.fromDF(df_w_timestamp, glueContext,
"df_etl_log")
return DynamicFrameCollection({"CustomTransform0": df_etl_log}, glueContext)
- Select from Collection (Custom Transform will always return a collection, so select item 0)
- ApplyMapping (this does not make an adjustment to default mapping, but is used to make sure that the order of the columns in the Redshift table is correct)
- Amazon Redshift (targets the table in Redshift using the Glue Data Catalog table created by Glue Crawler)
- IMPORTANT: Make sure that bookmarks are enabled, as they keep track of which S3 objects have already been loaded and allow a simple insert mechanism in the last component, which inserts into Redshfit.
Part 2:
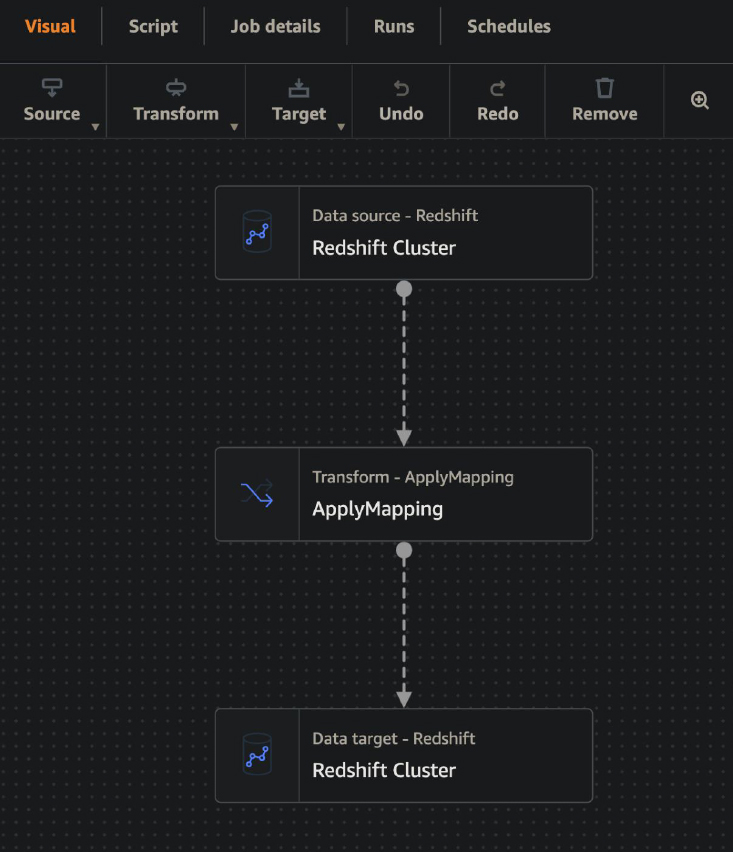
Here are the components and steps that we use to convert our intermediate warehouse tables to a final warehouse table along with a screenshot from Glue Studio:
- Redshift Cluster (delta set view in Redshift using Glue Data Catalog table created by Glue Crawler)
- ApplyMapping (this does not make an adjustment to default mapping, but is used to make sure that the order of the columns in the Redshift table is correct)
- Redshift Cluster (targets the table in Redshift using the Glue Data Catalog table created by Glue Crawler)
- NOTE: It is true that there is some inefficiency in the process of pulling delta set data from Redshift into Glue and then pushing it back into Redshift instead of calling a stored procedure in Redshift. We may eventually end up going that route, but we are sticking with this for now as we could easily copy the delta set to S3 or another location from this configuration. Delta set data should only contain new data that needs to be added to the final table, so there is not an unnecessary amount of data transferred in this process.
Wrapping It Up
To keep our process simple, we are running our jobs on a 10-minute schedule (the minimum recommended by AWS). This is working well, and we are no longer encountering the errors we saw with our previous method. We are looking into better ways to trigger and orchestrate our Glue-based pipelines. Also, we are continuing to evaluate and compare other approaches and toolchains, so stay tuned for a potential part two of this journey into data!
About the Author
Justin has been building high-impact business solutions, across multiple industries, for over nine years. He has experience with data engineering, full-stack web development, distributed systems engineering, and Kubernetes. He also dabbles in decentralized applications and machine learning. He maintains an intense drive to understand complex systems (technical and business), in combination with quick skill acquisition and the ability to grow teams.
Careers




